Marlin Cache
Introduction
Marlin Cache is a distributed event driven caching system for Dapps based on the observation that a small portion of contracts and addresses account for most of the on-chain activity and queries to the blockchain APIs. Therefore, by maintaining a small cache of frequently accessed data, a significant portion of the queries can be fulfilled locally without actually querying the blockchain.
Why should I use it?
The Marlin Cache provides the following benefits:
- Requests can be served from nodes much closer to the user, resulting in much better response times
- Requests can be served without the overhead of querying the blockchain data, again resulting in better response times
- A significant portion of the requests do not actually hit the origin, thereby giving much higher query rate at a much lower cost than the origin can reasonably support
How is this different from a CDN?
While the benefits offered by a traditional CDN are similar, they are fundamentally different in how they work.
It is very easy to cache static assets which change infrequently. Unsurprisingly, traditional CDNs are extremely effective in enhancing web and mobile performance for internet traffic, a large portion of which is assets such as HTML/CSS/JS files, images, videos and other media.
However, traditional CDNs cannot effectively cache frequently and unpredictable changing content like API responses. They usually work on the basis of a TTL (Time-To-Live) associated with every asset after which the asset is considered stale and purged from the cache. This brings in a fundamental tradeoff - if the TTL is too small, the origin is hit too often making the cache ineffective, if the TTL is too large, API responses would be stale and worse, inaccurate.
Modern CDNs which work well for APIs require specialized engineering as evidenced by the fact that very few traditional CDN providers provide caching for APIs and those that do charge a hefty premium.

The Marlin Cache overcomes this issue by being event-driven first and foremost with TTL-based mechanisms only as a backup. Combined with the Marlin Relay, this ensures that the cached data is updated quickly to reflect the state of the blockchain network and is never stale by a significant amount.
How is this different from Infura/TheGraph/Other API services?
It might be tempting to think of the Marlin Cache as a competitor to other API services, but its more accurate to look at it as a complementary offering.
Most API services like Infura are limited in terms of node distribution for a very good reason - running a distributed API service is very expensive in terms of operating costs. For example, Infura requires full nodes and TheGraph requires indexers in addition to full nodes (and sometimes archive nodes) which are pretty resource intensive to run. This makes it so the services are only profitable to run near users in a few locations with a large coverage area which affects response times - a fundamental cost vs performance tradeoff.
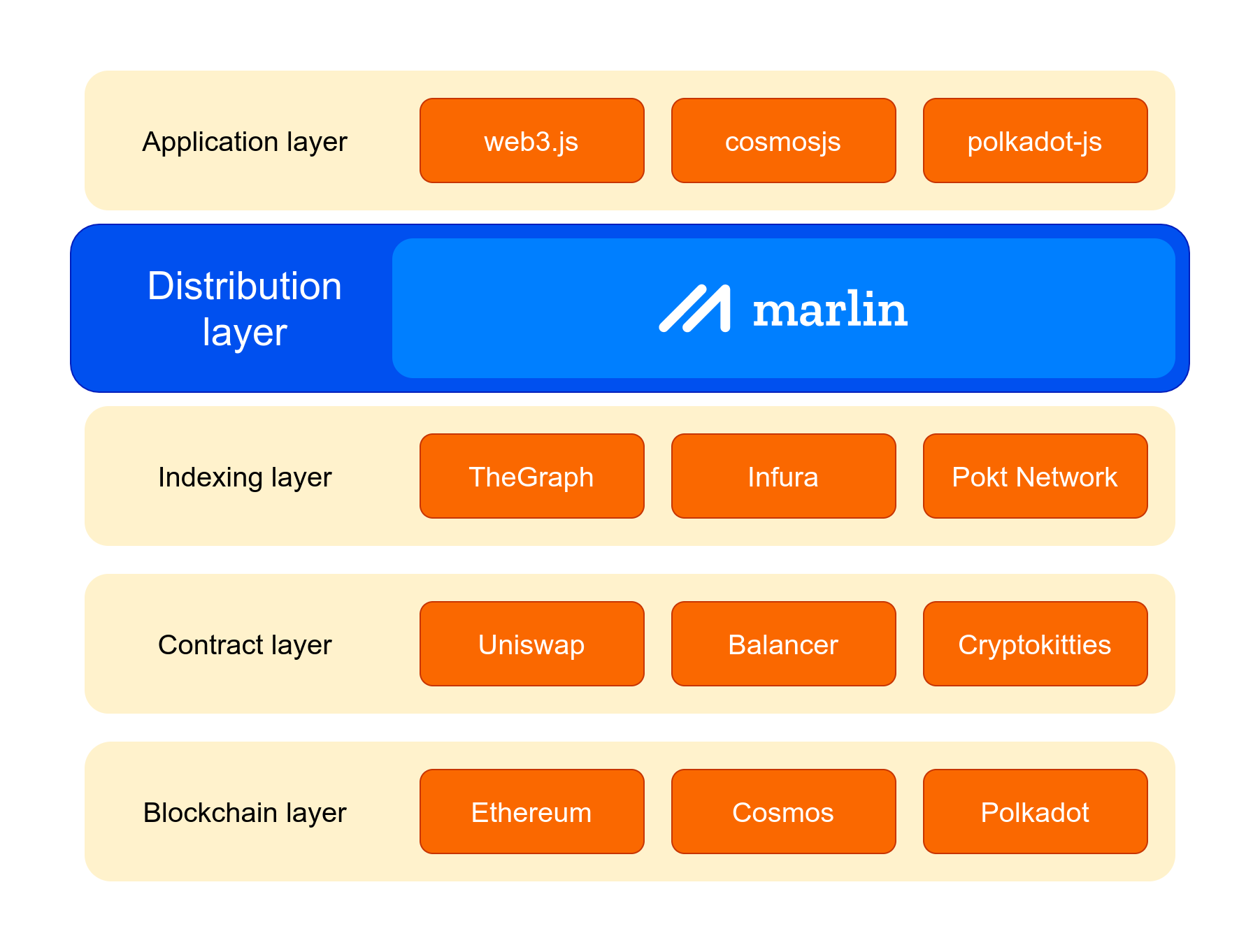
The Marlin Cache decouples indexing from the delivery. The Cache nodes can be much smaller and cheaper allowing them to penetrate much deeper and closer to end users. Moreover, nodes are free to cache and serve only a part of the origin's APIs/graphs which lowers the requirements further and makes it feasible for casual operators to run nodes. This can be easily extended to a hierarchical distribution of caches (not unlike CPUs today) to squeeze out maximum performance at a low cost.
How do I use Marlin?
The Marlin Cache currently supports the following origins:
📄️ Infura
Usage instructions to cache Infura queries
📄️ TheGraph
Usage instructions to cache Graph queries